TABLE OF CONTENTS
INTRODUCTION:
Background:
OTS clusters:
PVM:
MPI:
Mpich:
LAM-MPI:
Stock SC:
Intro:
CPLANT:
Structure:
Installation:
SCYLD BEOWULF:
Structure:
Installation:
SIMILARITIES:
Structure:
Installation:
DIFFERENCES:
Structure:
Installation:
CONCLUSION:
FUTURE:
REFERENCES:
INTRODUCTION:
This paper is about two projects that are both working toward similar goals. It will discuss what they are doing, how they are the same and how they are different. The two projects are both developing supercomputer operating systems. They are Cplant and Beowulf. Before I detail information about these two projects some background information would probably be helpful to most readers. If you are familiar with cluster OTS supercomputers you may want to skip the background section.
Background:
What is a supercomputer and why should I care? Well, supercomputers are the fastest type of computer. They are used for applications that require immense amounts of computational power. Examples of these applications are ocean and weather modeling, fluid dynamics, and nuclear simulations. Supercomputers differ from mainframe computers in that they work one problem at a time, whereas a mainframe supports multiple concurrent users.
When supercomputers were first developed they were typically single machines with shared memory and multiple CPU’s (SMP machines). They were custom built from the ground up and performed communication among processes using the shared memory. As opposed to this OTS clusters have local memory and perform communication by utilizing messages that are passed between the machines using the network. Two problems with shared memory machines that contributed to the rise of cluster supercomputers are, shared memory machines are expensive to build and they are not scalable.
The following sections on OTS clusters, PVM, and MPI (mpich and Lam MPI) are to provide information for clarity and later reference. The OTS section discusses the developments in the construction of supercomputers that led to Cplant and Scyld Beowulf. The sections on PVM and MPI (Mpich and LAM-MPI) show the dominant API’s (and implementations) that are utilized when setting up a cluster supercomputer. The stock SC section shows the approach that Cplant and Scyld Beowulf are offering an alternative to.
OTS clusters:
OTS stands for off the shelf. This refers to the fact that these (OTS) components can be purchased from vendors without having to be specially ordered. OTS parts are also referred to as "commodity parts". Commodity or OTS clusters are a group of computers linked together by some form of network, usually fast Ethernet or Myrinet, to enable message passing between them. In this way the cluster of computers can perform as one very powerful computer. The individual CPU’s perform work on one large problem in parallel.
There have been hybrid machines that are clusters of shared memory machines. These perform communication among the clusters using message passing and utilize the shared memory within individual machines for communication.
The shared memory model and the cluster supercomputer model are the two basic types of parallel computer architectures. Cplant and Beowulf both fall under the cluster supercomputer heading. This architecture (OTS clusters) is being developed as a result of the low price and high performance of commodity components. Neil Pundit manager of Cplant software development at Sandia National Labs states:
"Supercomputers for the past decade have traditionally been purchased as turnkey machines from the world’s largest computer makers. Such machines have cables, connection boxes, as well as monitors and testing equipment, already built in place. In Cplant, we are following a new path, assembling a supercomputer out of parts, open-source software, and our own developments."1
Rolf Riesen, also of Sandia states:
"This is another kind of revolution going on, that a major government laboratory like Sandia is willing to spend $9.6 million plus a significant amount of in-house development to make a supercomputer out of a supply of off-the-shelf parts."1
PVM:
PVM is a portable software API to support message passing. It predates MPI and was designed for a heterogeneous distributed computing model, the Parallel Virtual Machine (PVM). The control of the PVM API lies primarily with its authors. PVM supports language inter-operability. This means with PVM communication can occur between a C program and a Fortran program. PVM addresses fault tolerance through the use of a fault notification scheme. PVM has methods for starting and stopping tasks, and querying for location and status of tasks. These methods provide process control. The PVM approach to resource control is a dynamic one that allows for flexibility in dealing with changing computational needs during the execution of a program.
MPI:
The message passing interface (MPI) was developed to address the different API’s for message passing that were being used by each vendor of Massively Parallel Processor(s) (MPP). MPI is a library specification for message passing on diverse parallel machines. The design of MPI appears to have been valid, as MPI is now the dominant API being utilized to develop implementations for message passing on super-computers. MPI does not support language interoperability. Fault tolerance is provided using a notification method similar to the PVM scheme. The MPI interface has methods for starting and stopping tasks but does not provide for the querying of tasks. The MPI interface takes a static approach to resource management opting for performance over flexibility. MPI provides a high level of abstraction that allows for logical grouping of the underlying message passing topology.
Mpich:
Mpich is a freely available portable implementation of the MPI standard for parallel computing environments. This implementation supports many different designs including clusters of workstations (COW’s), and massively parallel processors (MPP’s). MPICH was developed at Argonne national laboratory and comes with a library of functions for the X11 window system, event logging, and visualization tools.
LAM-MPI:
LAM (Local Area Multicomputer) is a freely available implementation of the MPI standard. It provides an API of library calls for message passing between nodes of a parallel application. LAM-MPI also provides several debugging and monitoring tools. The LAM implementation of MPI runs on a wide variety of Unix platforms, from COW’s to dedicated super computers.
Stock SC:
I use stock SC to refer to a super computer that is not running a "cluster operating system" per se, but that is using an MPI implementation (Mpich or Lam-MPI) along with other tools to support the message passing and process control on a super computer. Typically the OTS super computer will be set up as a private subnet. The server (administration, front end) will have two network connections, one to the "outside world" (configured with a real IP address) and one configured for the private subnet. This administration node serves as the gateway to the world. Users log into this computer and compile, edit, and launch jobs from here. The private subnet consists of the compute nodes. These compute nodes are connected together using a private network that is not accessible to the "outside world". These nodes do the actual computation involved in the application, hence the name compute nodes. These compute nodes are usually setup in one of three ways, diskless, with local disks, or middle ground setup.
Diskless nodes have no local hard drive. They load their file system remotely from a network file system (NFS) server. This is desirable because when changes must be made to the file system they need only be done once instead of individually on every node. It is undesirable because it increases NFS traffic and requires a more complex initial setup of the server/administration computer. Also, as nodes are added, changes to the server may be more complex then if the nodes had local disks.
Nodes with disks do have a local hardrive. Their root file system, as well as an operating system, is loaded onto the local disk. This requires a more complicated initial setup of the nodes and concurrency between the file systems (on the nodes) becomes an issue.
Middle ground setup is just that, a solution that borrows from a diskless setup and also from a setup involving nodes with disks. In this setup the compute nodes each have a local hard drive with an operating system installed on it. They load their file system remotely from a (NFS) server/administration computer (like diskless nodes). This approach provides greater flexibility in the configuration of the compute nodes. For instance they may load their entire file system using NFS or simply mount parts of their file system remotely using the local disk to provide the rest.
These OTS clusters differ from COW’s in several important ways. The supercomputer is split into an administration node and a grouping of compute nodes. The administration node is the only computer that is accessed by the users. The cluster acts as one massive computer and the compute nodes are dedicated machines that only perform work together under the control of the administration node. With a COW the computers can work together on a problem, but they also can be utilized individually (my desktop computer at the Albuquerque High Performance Computing Center is part of a COW). Additionally the jobs that can be effectively divided for computation on a COW differ from those that can be run on OTS supercomputers.
Applications for supercomputers are usually designed using sequential programming languages (Fortran, C) extended by message passing libraries to enable parallelism. The application is split into different segments that are then run on the compute nodes at the same time (in Parallel). Each compute node is running a small part of the larger program. Depending on the program structure, more or less information will have to be shared among the nodes. This information sharing is accomplished through message passing using the network. In most large parallel applications this message passing quickly becomes the bottleneck in performing the computation. Eliminating this bottleneck is the subject of numerous current research projects.
Intro:
As opposed to the "stock SC" method of running a supercomputer there are two important projects under way to encapsulate, improve upon, and facilitate the installation of the "cluster operating system". These projects are an attempt to improve the performance of the running supercomputer and the ease with which the setup of such a computer is accomplished. These two projects are Cplant and Scyld Beowulf. The rest of this paper will discuss the structure and installation method of these two projects.
Cplant is a project at Sandia National Labs. It is a collection of code designed to provide a full-featured environment for cluster computing on commodity hardware components. Cplant system software is distributed as source code, which can be built for a specific hardware configuration. Sandia National Laboratories has designated Cplant as an open source software product.
Scyld Beowulf is a software package to provide simple cluster setup, integration, and administration. No other software is required to create the cluster. Thomas Sterling and Don Becker started Beowulf while working at CESDIS. CESDIS was located at NASA’s Goddard Space Flight Center. The Beowulf project is now hosted by Scyld Computing Corporation, which was founded by members of the original Beowulf team to develop and support Beowulf systems in the larger commercial arena.
CPLANT:
Structure:
The Cplant structure is similar to most OTS clusters. There is an administration node and compute nodes. The administration node acts as a gateway to the outside world and supervises users and jobs. The structure is hierarchical to promote scalability and flexibility. The Cplant installation at Sandia is set up using diskless nodes and a file I/O partition of nodes provides for secondary storage needs. Cplant can also be setup utilizing compute nodes that possess disks, or the middle ground approach.
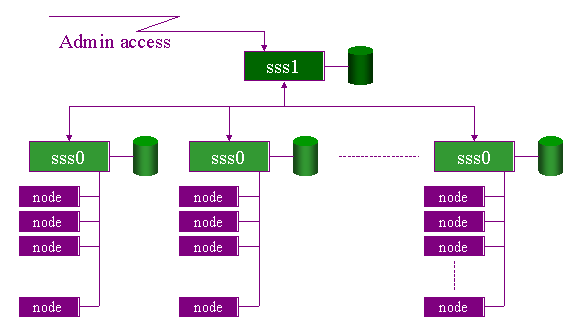
The hierarchical structure of Cplant is based on the concept of scalable units. The logical grouping of nodes into these scalable units is done in a tree fashion and allows for the addition (growing) and deletion (pruning) of Cplant, hence the name Cplant which stands for: computational plant. The administration node is connected to top-level service nodes which themselves are the top of a group of computers. This logical grouping is only for administrative uses and the user is not aware of this structure.
The hierarchical structure of Cplant5
Cplant (at Sandia labs) uses the diskless model of an OTS cluster. The file systems for the compute nodes are mounted remotely. The NFS file system does not use one centralized server to provide for all the compute nodes. Instead a file I/O partition of computers provides the file system to the compute nodes. Given that the system has N compute nodes and P file I/O nodes, each file I/O partition node would export the file system to N/P compute nodes. This division of labor helps to reduce NFS traffic and improve the scalability of the system.
Installation:
The official open source distribution of Cplant that is available for down load from Sandia National Labs consists of: Operating system code, Linux modules, drivers, application support libraries, compiler tools, an MPI port, user-level runtime utilities, and support scripts for configuring and installing the built software. The support and installation scripts are based mainly on the Make utility, along with Perl and Bash scripts. The basic steps involved in installing Cplant on a cluster are; obtaining the Cplant release; UN-archiving this into an appropriate directory; editing, configuring, and building the Linux/Cplant kernel; compiling and collecting the built binaries; and finally installing these binaries onto the administration node. What follows is an overview of the steps required during installation and should not be confused with installation instructions. For installation instructions please go to http://www.cs.sandia.gov/Cplant/doc/build/build.html.
The Cplant release can be obtained from Sandia National Labs at http://www.cs.sandia.gov/Cplant/. This tar file is the official open source distribution of Cplant. UN-archive this tar file into an appropriate directory and you have obtained the Cplant source code.
The install requires the user to obtain an appropriate version of the Linux kernel source code. Currently Cplant supports kernels 2.0.36, 2.2.13, 2.2.18, 2.0.35, 2.2.10, 2.2.14, and 2.2.19. This kernel source code should be placed into the Cplant directory structure and the correct Cplant patches copied on top of the Linux tree. The Linux/Cplant kernel must then be built and some soft links created. It should be noted that the kernel build and links creation has been automated for standard builds that take place at Sandia Labs using scripts, but these scripts are not suitable for off-site installations.
To build the Cplant components a Make utility is provided at the top level of the Cplant tree. This Make is a wrapper around the GNU make utility and it allows the user to specify what sort of a build to perform. The builds that can be chosen are basic, MPI, or user.
To install Cplant on an administration node three steps must be performed. The first is archiving and collecting the Cplant binaries/scripts that were built. The second is to transfer archived binaries/scripts to the administration node. The Cplant Make utility provides functionality for collecting the built binaries. The third is to UN-archive binaries and run a script that copies binaries to default Cplant VM tree in the directory /Cplant. This directory (/Cplant) is the Cplant file system that will be exported to the compute nodes. If necessary you must also generate and install Myrinet routes in the Cplant VM tree. A Cplant-map file must be created. This file is used to generate a hostname-to-node-ID mapping for use by the job launcher and other utilities. The Cplant-map files that are included in the distribution are for 8 node clusters. As with the Myrinet routes, it is up to the user to configure these properly using the documentation and samples included in the distribution.
The setup of the compute nodes differs depending on which method is used, diskless, with disks, or middle ground. The official source distribution does not include any scripts or samples to help with this process.
The installations at Sandia are on diskless clients (compute nodes). These installations use the boot protocol BootP to load kernels from a server. The Cplant file system is exported from the file I/O partition to the compute nodes. As such there is really no setup required for the compute nodes, other than information provided to the BIOS as to where to retrieve the kernel. Of course, the file I/O partition must be set up, and the complexity of this depends on the size of the cluster. With a small cluster size only a few file I/O nodes would be needed.
If the compute nodes are to be set up with disks, then they would each have their own copy of the Cplant file system. This would require archiving the Cplant file system /Cplant and moving and UN-archiving it onto each compute node.
With the middle ground approach the compute nodes have a local disk but load the Cplant file system from the administration node. This requires setting up the administration node as a file server as well as setting up the compute nodes to mount the Cplant file system remotely. This method is the most flexible and is probably preferable for clusters that are not too large. With larger clusters the NFS traffic becomes an issue and either re-exporting or a file I/O partition becomes necessary.
The cluster at the University of New Mexico in the SSL (scalable systems lab) is a port of the Cplant code to Intel machines. These machines have the Cplant kernel on disk locally and mount the Cplant file system from a server. Installation on these compute nodes involves installing the Cplant kernel, edits to /etc/fstab to mount the Cplant file system from the server, and edits of network scripts.
SCYLD BEOWULF:
Structure:
Not all Beowulf clusters are Scyld Beowulf clusters. Generic Beowulf clusters use commodity software like the Linux operating system, Parallel Virtual Machine (PVM) and Message Passing Interface (MPI). The server node is the cluster’s console and gateway to the outside world. Beowulf cluster compute nodes can be constructed diskless, with disk, or using the middle ground approach. The Beowulf team classifies systems into two groups the CLASS 1 distinction, which is a machine that can be assembled from parts found in at least 3 nationally/globally circulated advertising catalogs, and a CLASS II distinction, which is any machine that does not meet the above requirements. The typical setup of a cluster is to have a server (administration node) and a number of compute nodes. The compute nodes all run a local copy of some OS (Linux, Digital Unix, BSD) and get the user file space /home and /usr/local from the server. Users log into the administration node and edit, compile, and spawn their jobs. Beowulf has features, which help the users to see the Beowulf cluster as a single computing workstation.
The Scyld Beowulf system is intended for small clusters of 32 to 64 nodes. It is only installed on the administration node. Compute nodes receive a 1MB partial install. Network booting is the normal setup, but Myrinet, SCSI, CDROM and other kinds of boots are supported. The Mac addresses of the compute nodes are used to identify these nodes on the system. Hostnames are optional. Scyld Beowulf supports many types of file systems and NFS is not the default.
Installation:
Although some have the assumption (and the Scyld people have done nothing to discourage it) that you can put the Sclyd Beowulf CD into the administration node and it will install itself and set up the cluster. It really does not perform in such a simple and complete manner. But, The Scyld software is professionally packaged onto a bootable CD installation disk that is very user friendly. The main steps to installing the Scyld Beowulf software are installing Linux and Scyld into the administration node, making boot floppies for diskless compute nodes, booting the diskless nodes and configuring the administration node to communicate with and utilize the compute nodes
Installing the Scyld/Linux OS onto the administration node begins by placing the CD into the administration node and booting it up. The user is then presented with a graphical user interface (GUI). The GUI is almost identical to the typical Linux install with the same screens, user prompts, and choices.
The next step is to create bootable floppies for the compute nodes. Using beoSetup the user can create floppies for the compute nodes by simply clicking on a button; this puts a bootable kernel image onto the floppy. This kernel has its root device set to NFS root and will broadcast BOOTP packets to find an NFS root file system server when booted.
Before the compute nodes are booted, a program must be started on the administration node called beoSetup. This program listens for boot requests and provides the nodes with information such as their hostnames and IP addresses. A user enters the information provided to the compute nodes into the beoSetup GUI on the administration node.
The beoSetup program adds the compute nodes to the cluster as they are booted up. It sets up the communication protocols and lists the node as up or available for use. It would seem these steps, running beoSetup and providing the correct information, must be done each time the cluster is booted. However there may be a method to keep this information in the admin node for utilization on subsequent boots. I could not establish the existence of such a method and no documentation was available. This lack of documentation is discussed further in this paper in the differences section under installation.
SIMILARITIES:
Structure:
Cplant and Sclyd Beowulf have a similar basic structure. This structure is the same as the basic OTS cluster supercomputer. Both of them operate as a private subnet the administrative node controls access and provides functions for the user to operate the supercomputer. Message passing on the network is used to transfer/share information. Linux is the base of both systems.
Installation:
The only similarities in the installation methods of Cplant and Scyld Beowulf are that they both accomplish the task.
DIFFERENCES:
Structure:
The Cplant concept of scalable units (SU) is a significant difference. It allows for a new SU to be added or removed as the cluster grows and changes (replacing old machines with new ones). In contrast, the Sclyd Beowulf design is flat and may not support the heterogeneity involved if additions or replacements are made. Cplants use of a file system I/O partition also supports the ability to change and grow. In contrast, the Scyld software is not designed for large clusters of over 100 nodes. Cplant is designed to work with NFS and has avoided pitfalls of this by using the file system I/O partitions to distribute the workload. Scyld software is more flexible in this respect and allows the user to choose a file system.
Installation:
The differences between Cplant and the Scyld software abound. Cplant is user intensive. Cplant provides scripts to help with installation but the degree of automation when compared to the Sclyd CD is minimal. The Scyld software performs hardware probing and sets up the network connections between the nodes for the user. With Cplant the network connections must be manually setup by the user. However, as always, with standardization (install CD that does it all) comes a loss of flexibility. The Sclyd software comes with a particular version of Linux, the Cplant software supports many. If one needed to modify the installation procedure or basic structure of one of these two "cluster operating systems" I would argue Cplant should be preferred. My own experience with the Scyld software was that it was not completely user friendly. Many of the programs did not perform as they should have and the degree of automation makes this hard to troubleshoot and fix. With scripts and manual tasks troubleshooting and problem solving is much easier then with a program that does not allow user modification. Scyld is a commercial product. To obtain documentation the complete (expensive) version must be purchased. This user contacted the Scyld Corporation and explained the need for documentation to facilitate academic research and was told: "We do not sell our documentation separately, so unless you purchase our Basic or Professional edition, you won’t be able to obtain documentation. Sorry." Cplant is open source. The code and documentation are freely available. The rational for this is, that through widespread use of the software, feedback will be gained and development will be encouraged.
CONCLUSION:
The Cplant software is user intensive to install, but still is simpler to install and get working than setting up a cluster completely ad-hoc. If the Sandia model is followed, Cplant scales very well (I think they are up to 2000 nodes). Cplant structure and the packaging of the software itself make it extremely flexible. Cplant software is easy to troubleshoot and fix. Originally designed for Alpha machines, ports of the Cplant software have been made to Intel machines.
There is no doubt that the Scyld software is easy to install and run. Building an ad-hoc supercomputer is much more difficult. Packaging together the Linux and cluster modules in one install package is extremely convenient. The automation of the network (Ethernet and Myrinet) is also very convenient. Scyld software represents a huge leap in automatic installation of cluster operating systems. As always in computer science there is no win-win situation and tradeoffs must be made to gain the desired benefit.
FUTURE:
There is work being done at the Scalable System Lab (SSL) at the university of New Mexico to design and implement "Transient Cplant". This is an installation of Cplant on an operational supercomputer that leaves the current cluster operating system intact. This allows for the organization or company running the cluster to try the Cplant software with minimal commitment. Given that most supercomputers are in high demand by users who cannot afford an interruption in service, this could prove to be truly beneficial to the propagation of Cplant onto more supercomputers. Once the organization has tested the Cplant software they will be more likely to either make the switch to a full installation, or use Cplant on subsequent supercomputers.
The work on transient Cplant is also an attempt to make the Cplant/Linux kernel build more automatic by using hardware probes and typical settings to generating a Linux/Cplant configuration file. The work on Transient Cplant is also providing scripts that will automatically make the changes necessary to run transient Cplant on the operational supercomputer. The SSL is also porting Cplant to HP Itanium machines.
Future work for the Scyld Corporation includes Web based remote administration, checkpointing and checkpoint restart, and a port to the IA64 architecture.
REFERENCES:
1. Cplant In The News
http://www.sandia.gov/LabNews/LN08-11-00/c Cplant_story.html
2. Building, Installing, and Running Cplant Software
James Otto
http://www.cs.sandia.gov/c Cplant/doc/build/build.html
3. Beowulf HOWTO
Jacek Radajewski and Douglas Eadline
http://www.ibiblio.org/pub/Linux/docs/HOWTO/other-formats/html_single/BeowulfHOWTO.html
4. Beowulf Installation and Administration HOWTO: Quick Start
Jacek Radajewski and Douglas Eadline
http://beowulf-underground.org/doc_project/BIAA-HOWTO/Beowulf-Installation-and- administrationistration-HOWTO-1.html
5. Cplant website
http://www.cs.sandia.gov/Cplant/
6. Building a Beowulf System
Jan Lindheim
http://www.cacr.caltech.edu/beowulf/tutorial/beosoft/
7. PVM guide
Clay Breshears
Copyright © 1991, 1992, 1993, 1994, 1995 by the Computational Science
Education Project
8. Parallel Virtual Machine (PVM)
Feng-Chao Yu, Nov. 23, 1999
http://carbon.cudenver.edu/csprojects/csc5809F99/class_projects/
feng_chao_yu/full_project/vs.htm
9. LWN Feature Article
Donald Becker’s keynote
http://lwn.net/2001/features/Singapore/becker.php3